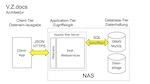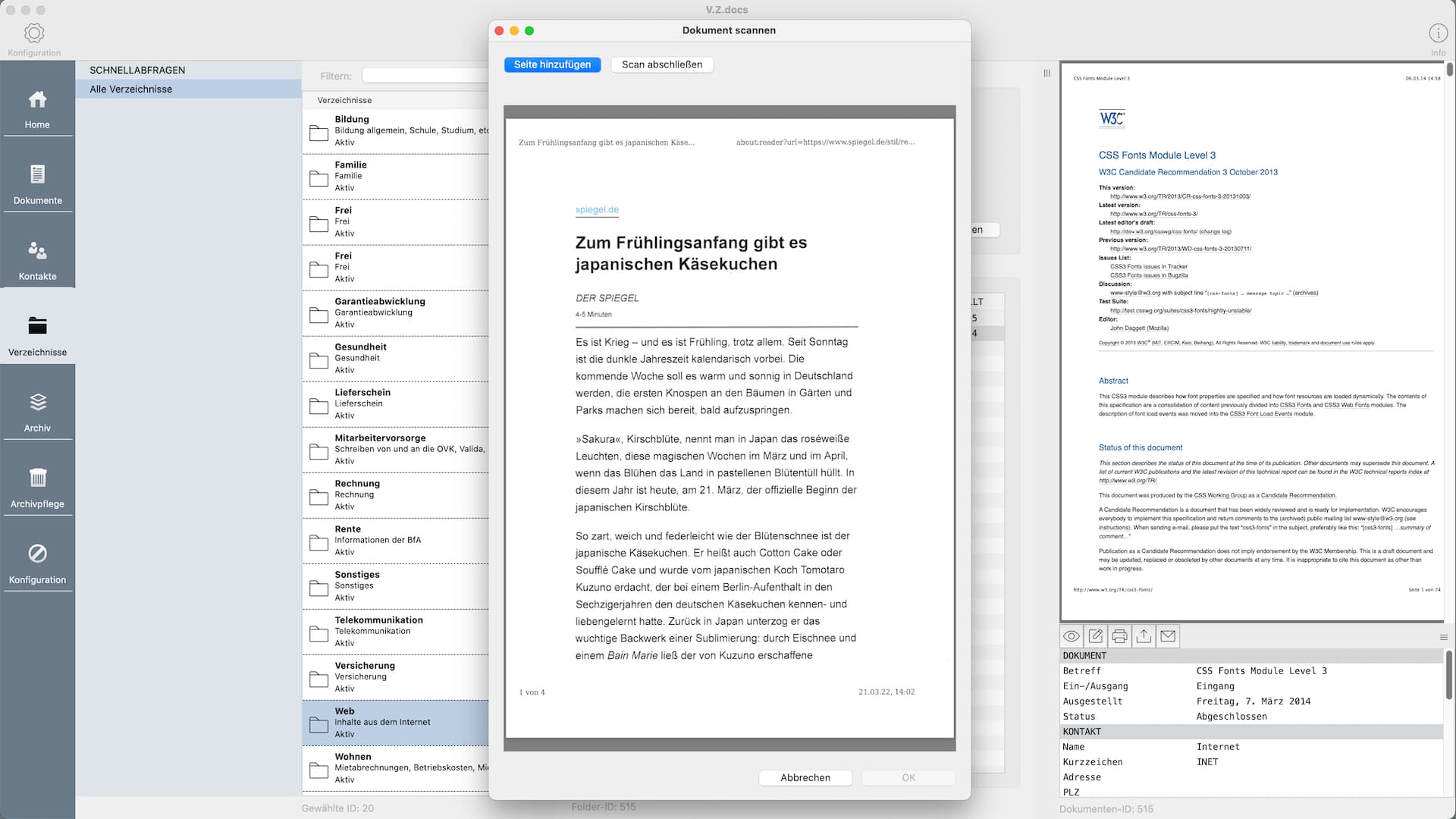
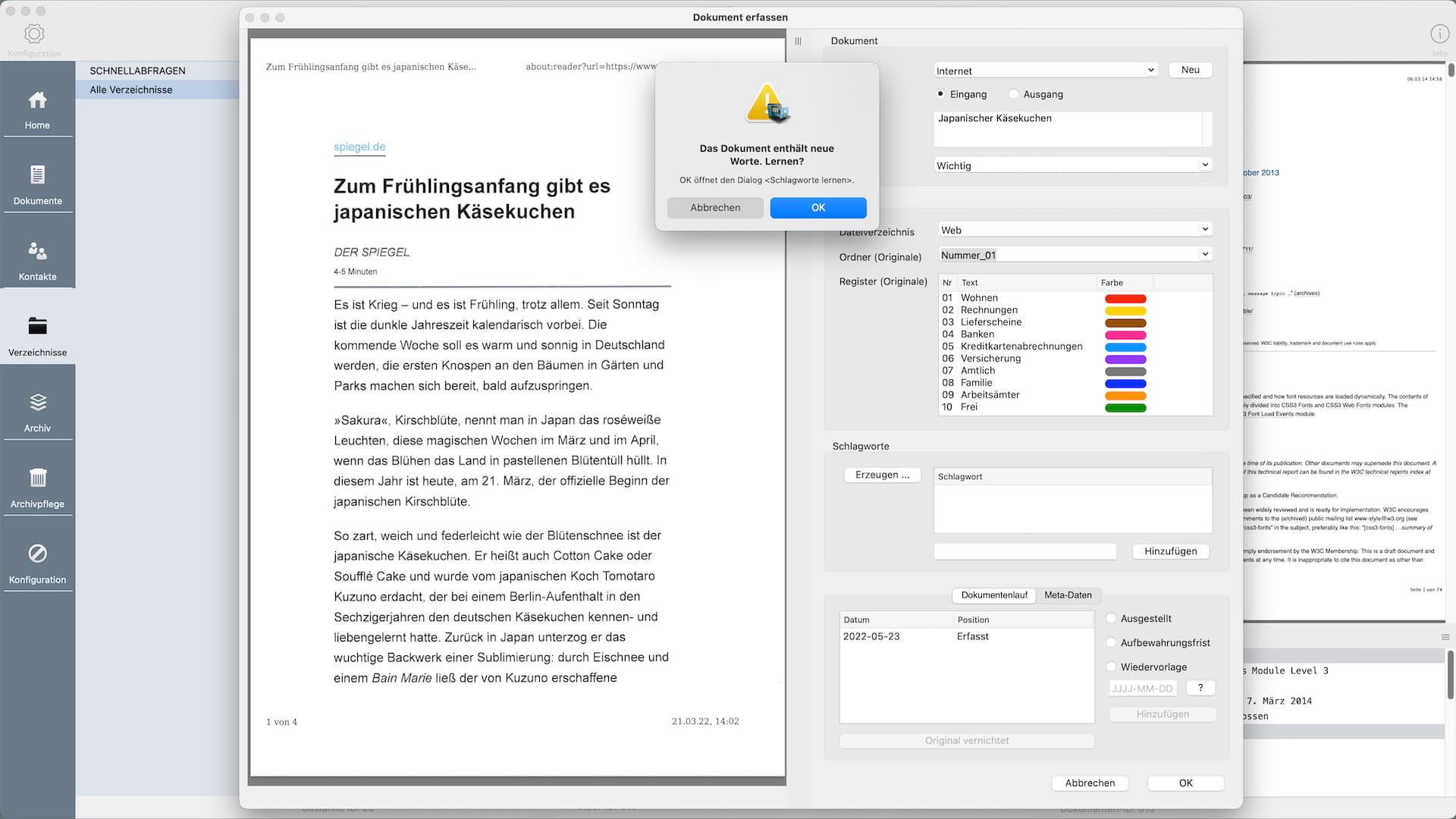
Das Scannen von Dokumenten ist eine Kernfunktion von V.Z.docs. Die zweite Möglichkeit, Dokumente im System zu speichern, ist der Import vorhandener PDF-Dateien.
Für das Scannen verwende ich das macOS-Befehlszeilenprogramm scanline (https://github.com/klep/scanline).
Die PDF-Dateien erhalten einen durchsuchbaren Textlayer. Hierfür verwende ich pdfsandwich (http://www.tobias-elze.de/pdfsandwich/).
Enthält das Dokument mehrere Seiten, so werden sie nach dem Scannen mit PDFtk zu einem zusammengesetzt (https://www.pdflabs.com/tools/pdftk-the-pdf-toolkit/).
Das erwähnte pdfsandwich erzeugt keine OCR-Daten. Für OCR verwende ich Tesseract (https://github.com/tesseract-ocr/tesseract).
Bevor Tesseract gestartet wird, muss das PDF in eine TIFF-Datei migriert werden. Hierzu benutze ich ImageMagick (https://github.com/ImageMagick/ImageMagick).
Vom Papier bis zum fertig erfassten PDF-Dokument ist der Prozess im Prinzip wie folgt:
- Scanner suchen: scanline -list> Bei positiver Rückmeldung
- Dokument einscannen: scanline -flatbed -resolution 300
- Textlayer erzeugen: pdfsandwich -lang deu -rgb
- (Mehrere) PDF-Dateien zusammenfügen: pdftk cat output
- Für OCR das von PDF nach TIFF: imagemagick/convert -quality 100 -density 300 -background white -alpha remove
- OCR durchführen: tesseract tiff.tif -l deu, das Ergebnis wird in einer Textdatei zwischengespeichert)
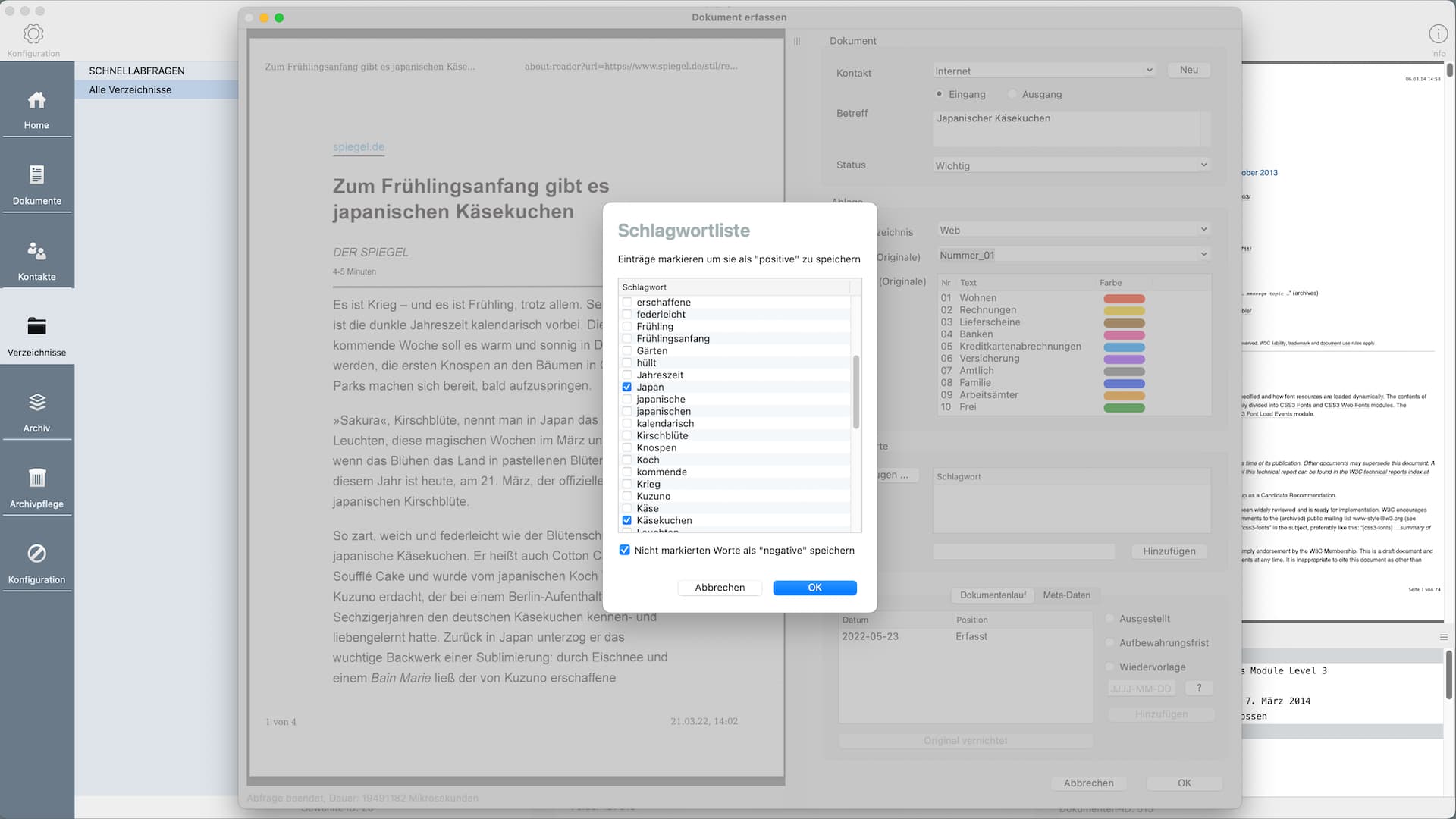
- Autom. Verschlagworten: Liste der positiven Worte aus der Datenbank in ein Wort-Array laden
- Autom. Verschlagworten: Liste der negativen Worte aus der Datenbank in ein Wort-Array laden
- Die zwischengespeicherte OCR-Textdatei wird bereinigt (Satzzeichen, einzelne Sonderzeichen usw. entfernen) und es wird ein Wort-Array gebildet
- Aus dem Wort-Array werden Worte < 4 Zeichen und Mehrfachnennungen entfernt
- Die Arrays der positiven und der negativen Worte werden mit dem Wort-Array aus dem Dokument abgeglichen. Negative Worte werden nicht berücksichtigt. Positive Worte werden als Schlagworte vorgeschlagen.
- Worte aus dem Dokument, die nicht im Array der positiven oder negativen Worte vorkommen, werden zum Speichern als positive oder negative Worte in der Datenbank vorgeschlagen
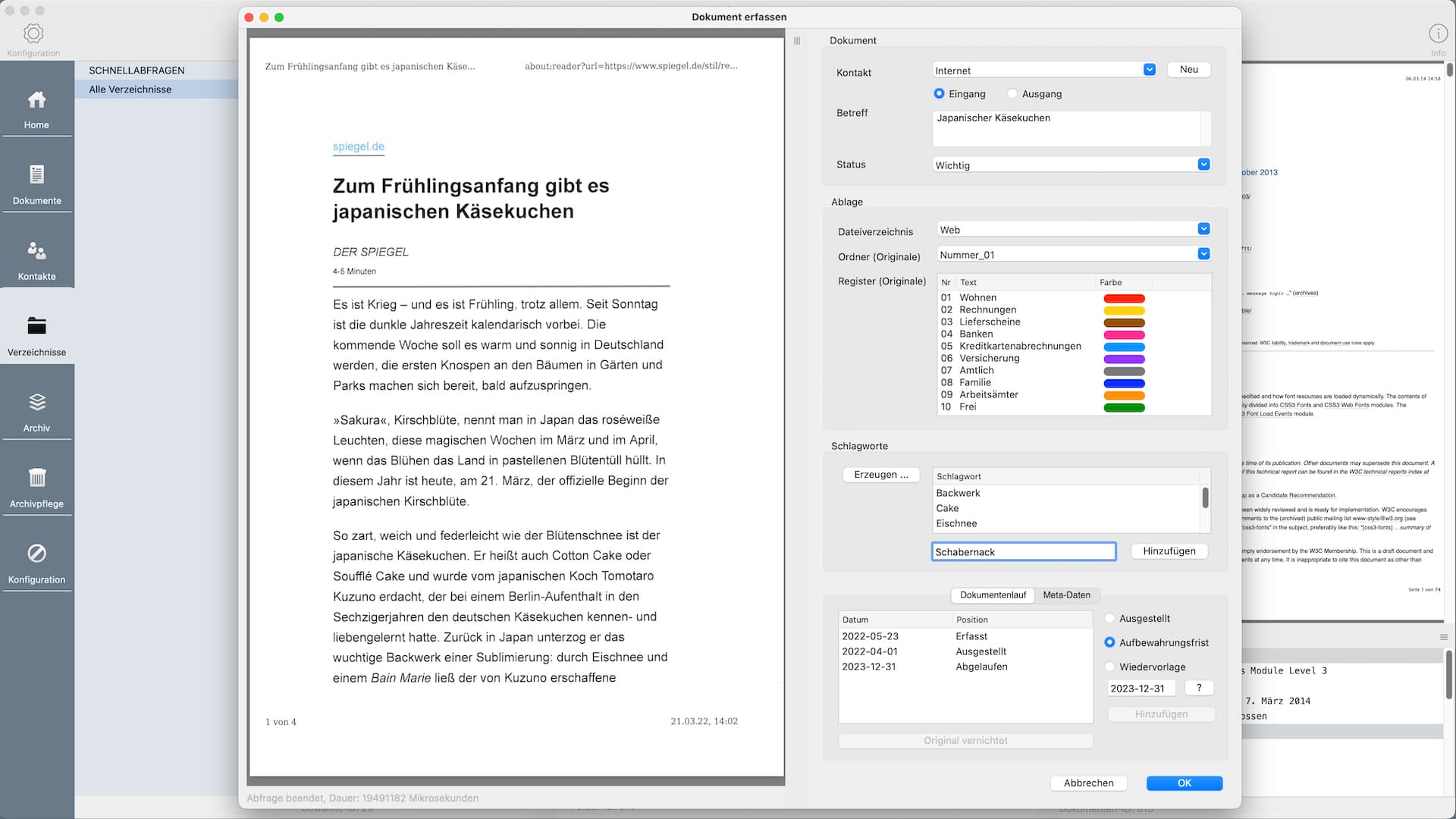
- Eventuelles, manuelles hinzufügen von Verschlagworten
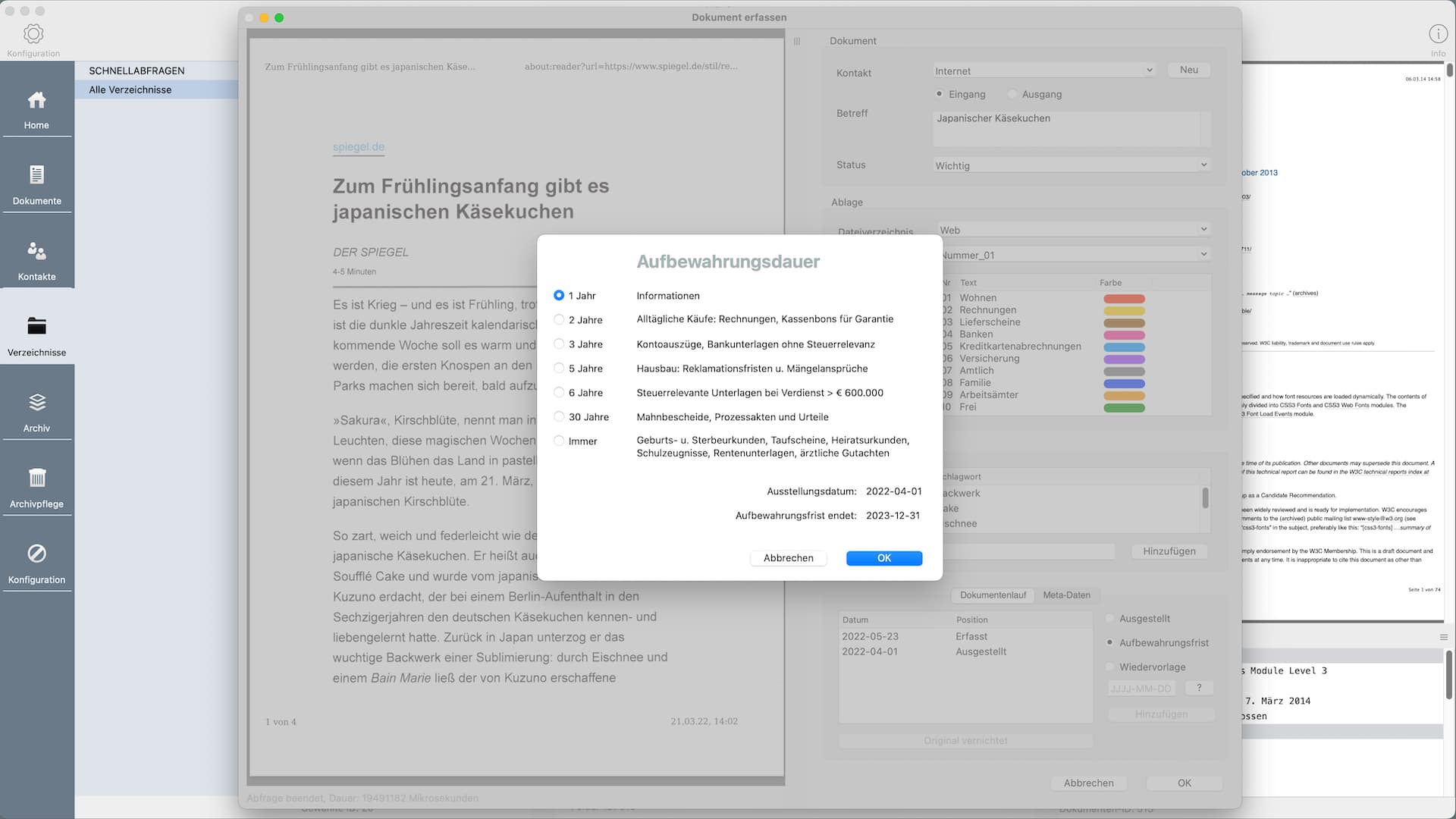
- Speichern der Dokumentdaten in der Datenbank, verschieben der PDF-Datei vom Arbeitsverzeichnis ins Zielverzeichnis
Bis das Bereinigen der OCR-Textdatei gut funktioniert hat, waren einige Durchläufe und Analysen des Ergebnisses erforderlich. Mittlerweile wird der "Noise" aus dieser textdatei aber zu fast 100% entfernt.
Das Verschlagworten über zwei Datenbanktabellen (positive Worte und negative Worte) ist im Prinzip ein selbstlernendes System. Mit einiger Konsequenz beim Kategorisieren der worte und ca. 100 erfasste Dokumente verschlagwortet der Prozess völlig zufriedenstellend.